画像認識– tax –
画像認識とは、写真・動画・スキャン画像などのデジタル画像から、物体・人物・文字・シーンなどの情報をコンピュータが自動的に識別・分類する人工知能技術です。畳み込みニューラルネットワーク(CNN)の発展により認識精度が飛躍的に向上し、近年はVision Transformer(ViT)など新たなアーキテクチャも台頭しています。
技術的には、画像分類(画像全体のカテゴリ判定)、物体検出(画像内の物体の位置と種類の特定)、セマンティックセグメンテーション(画素単位の領域分類)、顔認識、文字認識(OCR)など、目的に応じた複数の手法が体系化されています。製造ラインの外観検査・不良品検出、医療画像の診断支援(CT・MRI・X線の読影補助)、小売業の棚割分析・商品認識、防犯カメラの映像解析、自動運転における環境認識などが代表的な応用例です。
画像認識の実用化は、2012年のImageNetコンテストでCNN(AlexNet)が従来手法を大きく上回った出来事を転換点として加速しました。国内のソリューションでは、HACARUS Check、AdaInspector Cloud、Impulse、AMY InfraChecker、VisionPoseといった業務特化型の外観検査・姿勢推定システムや、Morpho、サイバーコアといった汎用画像認識SDKが代表例です。GPT-4VやGeminiなどマルチモーダルLLMの普及により、自然言語で画像を理解・質問応答する新しい利用形態も広がりつつあります。
-

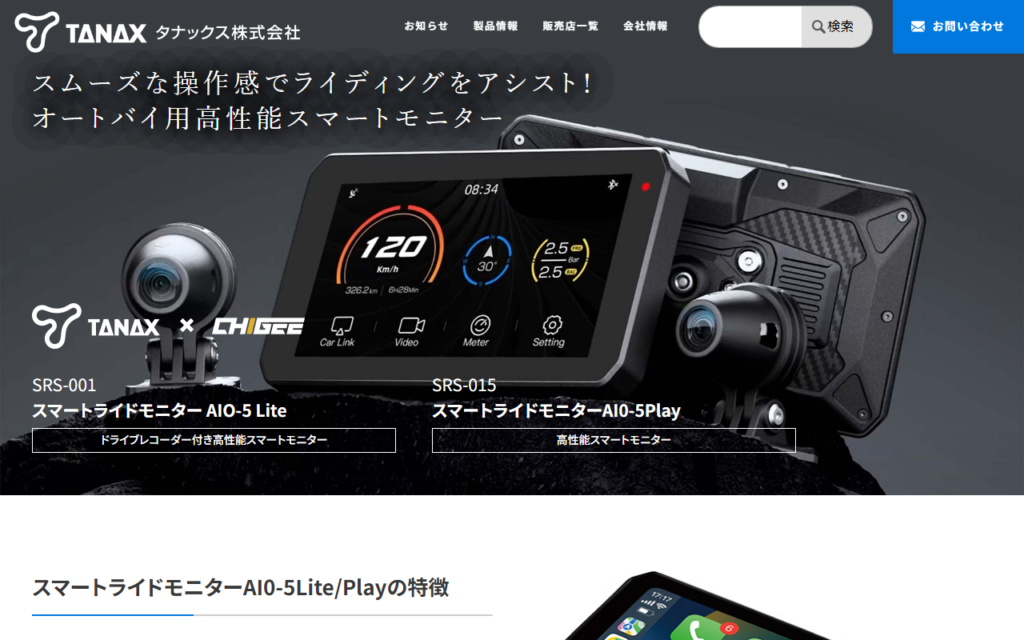
AIO-5 Lite / AIO-5 Play
オートバイ専用のオールインワン型スマートモニターです。5インチタッチパネルディスプレイに、ドライブレコーダー、ナビゲーション、安全支援機能を統合しています。BSD(死角監視システム)により左右後方・真後ろから接近する車両をAIで自動検知し、ラ... -
AIマイストーリー
合同会社Chibariyoが開発する「AIマイストーリー」は、顔写真からオリジナルマンガを生成できるAI体験型コンテンツです。最新のAI技術を用いたフェイススワッピングにより、ユーザーの顔を自然かつ高精度にマンガキャラクターへ反映させ、自分自身が主人公... -
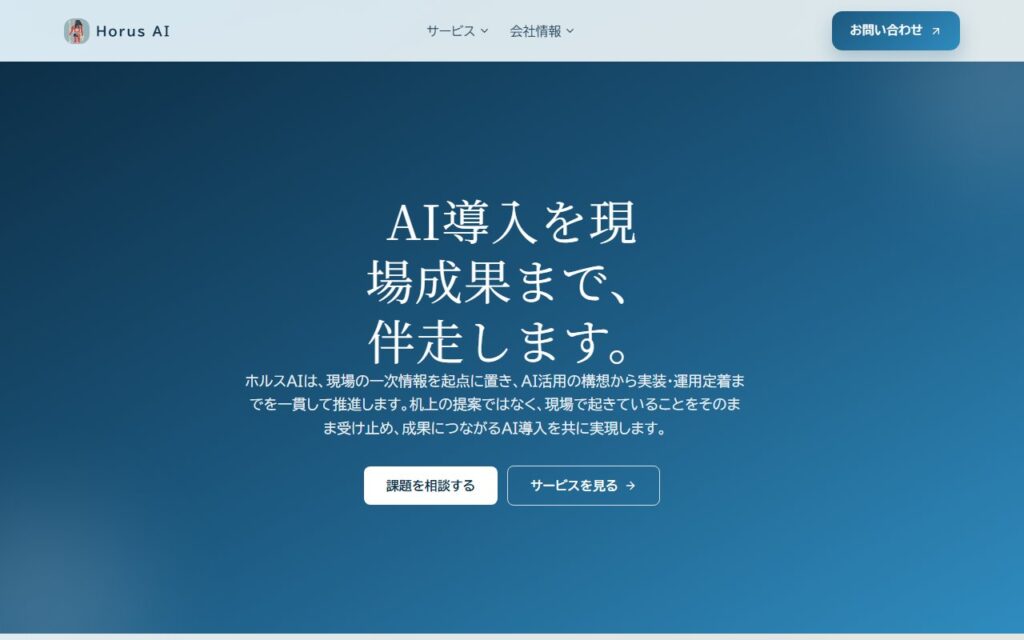
Zumen AI
ホルスAI株式会社が提供する「Zumen AI」は、製造業向けのAI図面解析・3Dデータ化支援サービスです。AIを活用して図面の解析と3Dデータ化の初動工数を削減し、見積業務の効率化や形状把握を支援します。板金加工における展開計算や曲げ干渉確認、めっき・... -
ANICRA
株式会社CrestLabが開発する「ANICRA」は、生成AIを活用した次世代アニメ制作支援基盤です。動画・仕上工程をAIでサポートすることで制作全体にゆとりを生み出し、作品のクオリティ向上のための時間と余力を創出します。複数のアニメスタジオとの実証実験... -
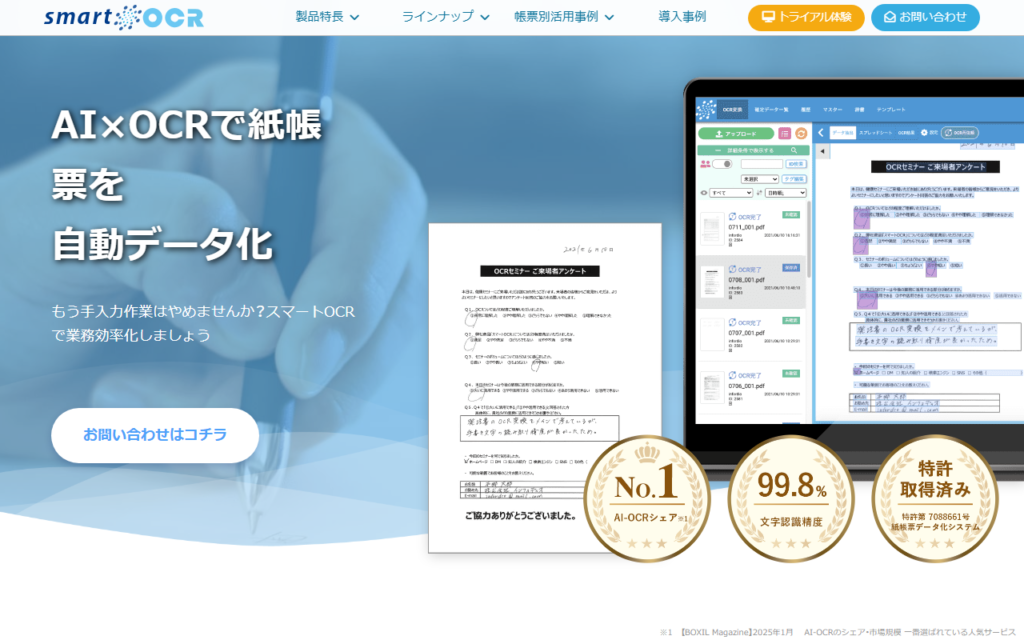
SmartOCR 健康診断書
スマートOCR SDクラウドは、健康診断書・人間ドック結果をAI-OCRで高精度にデータ化するサービスです。紙の診断書をスキャンするだけでAIが項目を認識・抽出し、保険会社の引受査定業務を大幅に効率化します。保険業界特有の帳票フォーマットに対応した学... -
LIQUID eKYC
LIQUID eKYCは、AI画像認識と生体認証技術を活用したオンライン本人確認サービスです。運転免許証やマイナンバーカードの撮影またはICチップ読み取りと、セルフィーの顔写真照合を組み合わせることで、本人確認をオンラインで完結させます。金融機関の口座...